Although I work for a mostly remote work company, a couple of times a year we meet together for a week in some nice location of the world. When that happens, multiple meetings across people in different teams are organized. Sometimes the number of requested sessions gets out of hands and the scheduling team is overwhelmed. Quoting them in one of our latest gatherings: “We currently have over 160 proposed breakout sessions which will be impossible to schedule unless we work until midnight every day! We only have 3-4 hours available for breakout sessions each day.”
The problem with scheduling these meetings is that you get a mix of people from different teams so you have incompatibilities between meetings, and some persons are invited to many meetings and it becomes hard to solve all of these conflicts so all the invited people can join their meetings. So, it seemed an interesting problem and I wondered if I could find a way to solve this in an automated way.
The way I thought about the problem was that I needed to assign meetings to time slots, minimizing the number of these slots while at the same time making sure that meetings at the same time slot were compatible.
The first approach one can think about is simple brute force: go across all possible options and select one that produces the minimal number of time slots (note that it is possible that there is more than one optimal solution). To find all combinatorial options, first we can create all possible sets containing a given number of meetings. If we have \(N\) meetings, we can create all the \(K\) possible sets of meetings by first making sets that contain only one meeting, which is \({N\choose 1}\), then creating all possible sets that contain two meetings, which is \({N\choose 2}\), and so on, having finally \(K\) sets that is
\[K=\sum_{i=1}^N {N\choose i}\]
These sets could represent meetings that would happen at the same time slot. Of them, only the ones containing compatible meetings will be valid. Compatibility is easy to find out: if no meeting invitees for two meetings are shared, those meetings are compatible. We will call the number of valid meeting sets \(K_c\). Once we have them we can create other sets that contain, similarly, all possible combinations of these meeting sets. We can call them time slot sets. All possible combinations would give us the number \(L\):
\[L=\sum_{i=1}^{K_c} {K_c\choose i}\]
Each of these time slot sets represent possible solutions to the problem, being the cardinal of the set the number of time slots that would be needed. However, not all combinations of time slot sets will be valid solutions: only the ones where no meeting is repeated across its meeting sets while at the same time all meetings are present will be valid. Among those, the combinations that have a minimal cardinal will be optimal solutions we want to find.
This is a correct way of finding a solution, however the number of combinations that we need to explore when we have more than just a few meetings can be daunting. Assuming a very optimistically low \(10\%\) of valid sets of meetings, so \(K_c=0.1 K\), we would have for, say, number of meetings \(N=5, 8\), and \(10\) a number of sets of time slots \(L=7, 3.36 \cdot 10^7\), and \( 5.07 \cdot 10^{30}\). We can see how the numbers grow extremely fast, and that searching through all of them would take a lot of time and computer memory and become unfeasible very quickly.
So, we really need something better than pure combinatorics. Something that can help with this sort of problem is to try to visualize it to obtain some insight on how it could be solved, and I followed that route. In this case we can use non-directed graphs in a straightforward way: we can make each meeting a node, and connect with edges compatible meetings. I will explain this with an example. Let’s say that we have 8 people to which we will assign letters A to H and they attend 8 different meeting with different attendees. Attendees per meeting are as shown in the following table:
Meeting 1
A, E
Meeting 2
B, F
Meeting 3
C, G
Meeting 4
D, H
Meeting 5
B, C, D
Meeting 6
A, C, D
Meeting 7
A, B, D
Meeting 8
A, B, C
From the table we can calculate the adjacency matrix of the graph, where each row will show the compatibility between a meeting and the others, having a \(1\) if compatible or \(0\) if incompatible. We will obtain a symmetric matrix. In our example:
For instance, from the first row we see that meeting \(1\) is compatible with meetings \(2, 3, 4\) and \(5\). The graph that would result from here is:
The problem is transformed now into trying to find out how to group nodes that are one edge away of each other in sets, in a way that minimizes the number of sets while all nodes are included in some set and there is no overlap across sets. These groups of nodes would be in a single time slot of the schedule, and we will call such sets simply “slots”. Possible slots for this example would be \(\{1,5\}\), \(\{1,2\}\), or \(\{1,2,4\}\), but not, for instance, \(\{1,2,5\}\) as \(2\) and \(5\) are incompatible.
Different strategies con be tried to create such sets. The one that gave me best results was what I called a “removal strategy”. We start with each node being assigned to a different slot, and then we try to remove the maximum number of slots. We do that by iterating on the slots and checking if it is possible to move all nodes inside a slot to other already existing slots. If that is the case, we assign the nodes to those slots and remove the slot that contained them. The iterations will repeat until there is a point in which it is not possible to remove more slots. In the previous example, a possible evolution would be (each color represents a different time slot):
1. Each node gets assigned its own slot, that we will designate by colors in the image.
2. We look at the “blue” slot. We find that its only node (1) can be assigned to other slots (“red”, “green”, “beige”, or “violet”). Arbitrarily, we assign node 1 to the “red” time slot and remove “blue”.
3. We look at the “beige” slot. We find that its only node (4) can be assigned to other slots (“red”, “green”, or “brown”). Arbitrarily, we assign node 4 to the “green” slot and remove “beige”. We then look at “violet”, but it is not removable because of the only connected slot, “red”, one of its nodes (2) is not compatible with 5. We go through “orange”, “yellow”, and “brown”, but we are in similar situations and they cannot be removed.
4. We look now at “red”. We see that its two nodes can be assigned to other slots (1 can be assigned to “violet” or “green”, 2 can be assigned to “orange” or “green”). Arbitrarily, we assign 1 to “violet” and 2 to “orange”, and we remove “red”.
5. We look now at “green”. We see that its two nodes can be assigned to other time slots. Arbitrarily, we assign 3 to “yellow” and 4 to “brown”, and we remove “green”. We start another iteration and look at the four remaining time slots, but we find that none of them can be removed as we cannot assign all its nodes to alternative slots. Therefore, the algorithm finishes at this point. We went down from 8 to 4 slots, each of one with two meetings.
We have find a solution in just two iterations, instead of having to go through millions of combinations!
I went forward with this idea and implemented it in go. The implementation is not complicated and can be found in this github repository, which also contains some instructions on how to run it. The program accepts input in CSV format and outputs CSV as well, so the data can be easily exported/imported from any spreadsheet. More details on the format can be found in the README.md file.
The complexity of the algorithm is \(O(N^2)\) because of the calculation of the adjacency matrix, but the maximum number of iterations of the removal strategy is just \(N\). Convergence is assured as you obviously cannot remove more than \(N-1\) slots. However, the algorithm does not always find the optimal solution, as we can find counter examples for this. For instance, if by using the removal strategy we end up with the following graph (again colors represent slots):
Figure 6
We can see that the algorithm will not process further the graph (no slot can disappear by assigning nodes to others). But, this one graph:
Figure 7
does have less slots (5 vs 6). There are some things that I think could improve the algorithm though. The first idea I have is, instead of assigning arbitrarily nodes to other slots when we remove, we could choose the one with less nodes amongst the possibilities, so distribution is more “even”. The second would be to proceed to further optimizations after applying the algorithm once by selecting neighboring slots, and then assign where possible nodes from them to the rest of the slots. With the remaining nodes, proceed with the removal strategy, and check if some slot consolidation happen. If that’s the case we would end up with less slots that those selected first. Doing this with the graph from Fig. 5 would actually lead to Fig. 6 after applying these steps to the green and orange slots. However, I doubt that arriving to an optimal solution is guaranteed even with these changes.
To finalize, I applied the algorithm to the original problem that inspired this blog post, and I was able to squeeze 158 meetings in 22 time slots in a fraction of a second, in just 3 iterations (it was nice to see that the very fast convergence happens also in more complex cases than the example). So it turns out that assuming we could have 4 hours for these meetings per day, we would not have been able to organize the schedule without some conflicts… although for a very small margin!
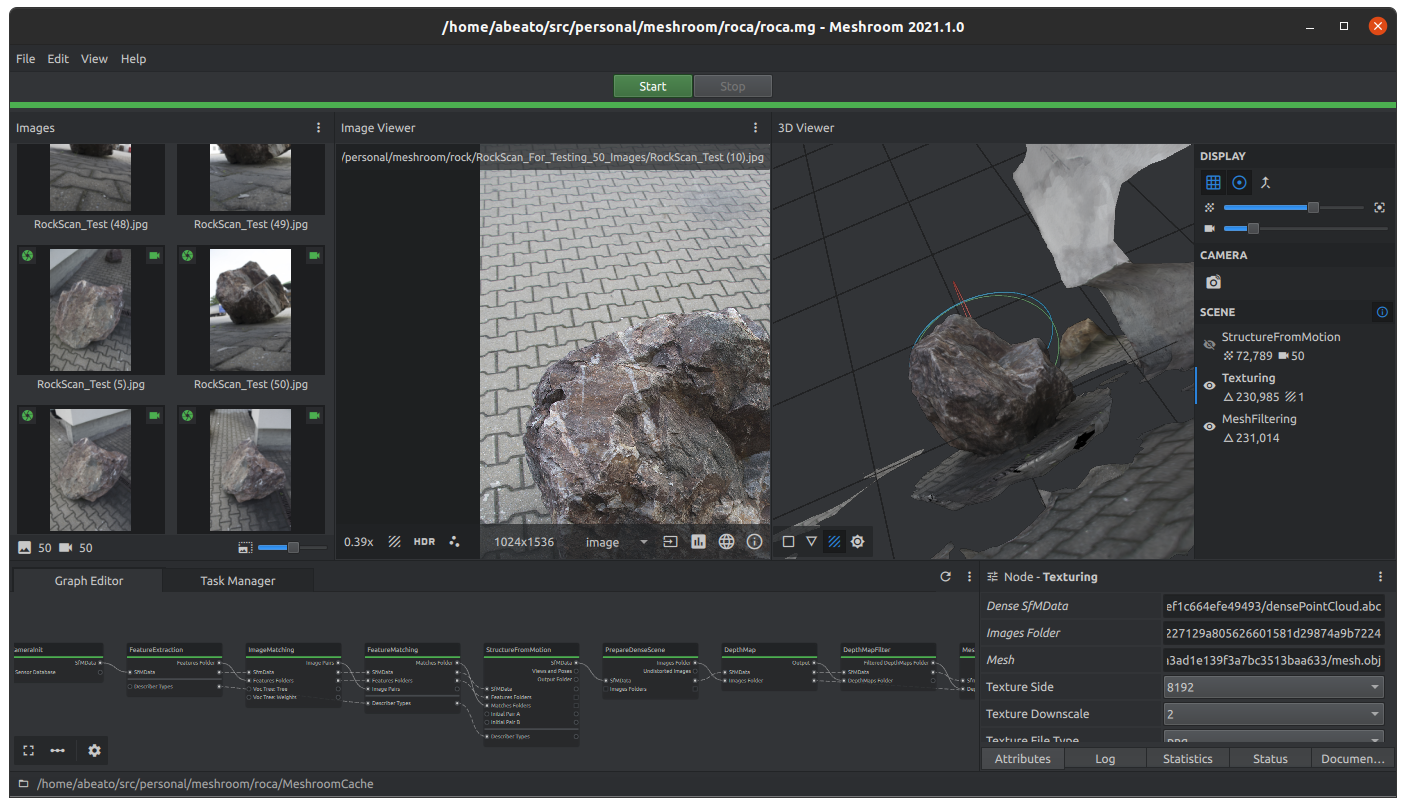
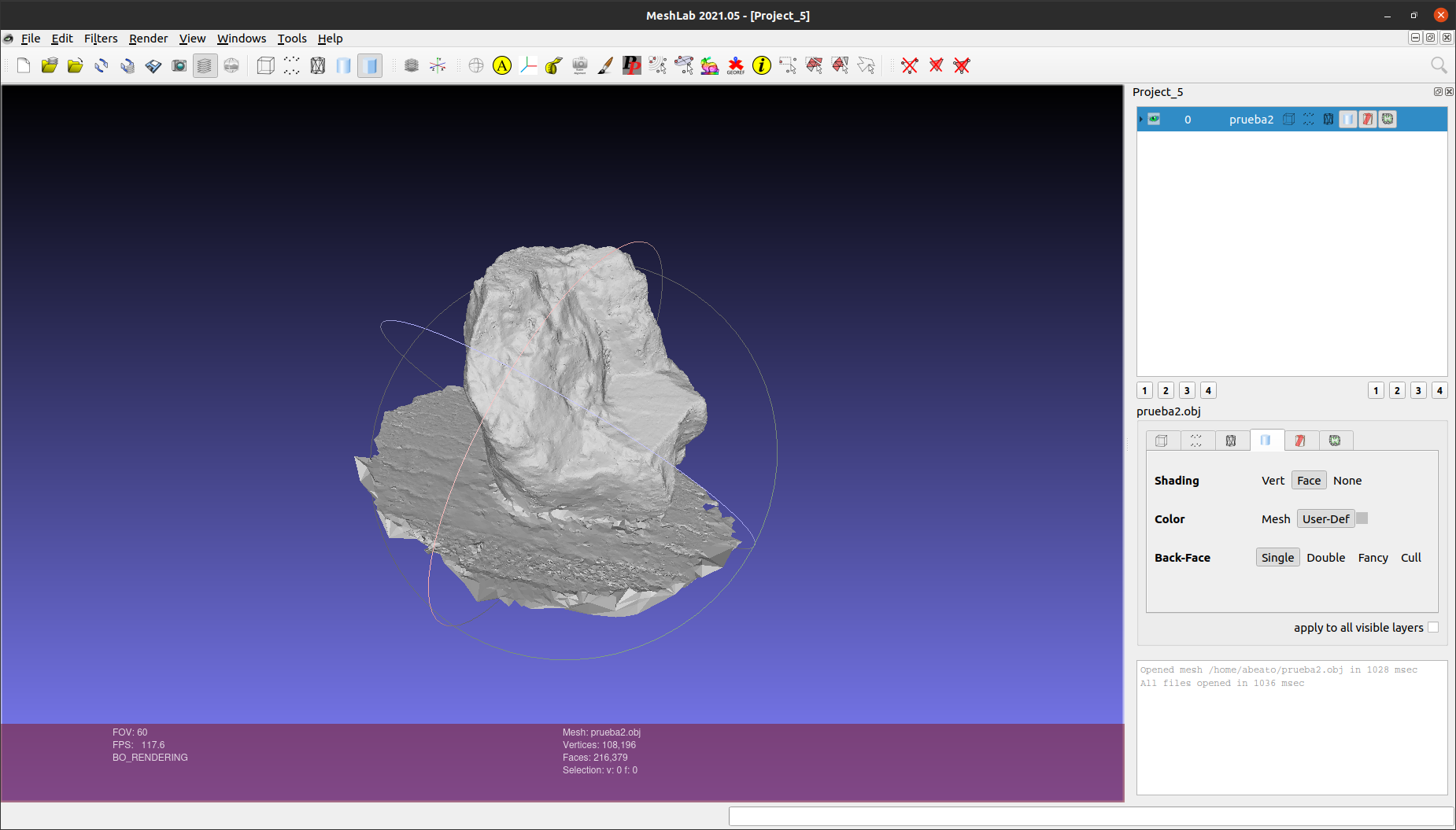
I have some interest in photogrammetry, and, more concretely, in the ways to extract 3D information from a set of photographies of an object. There is excellent open source software that is able to do this, like Meshroom, which is based on the Alice Vision framework. Once you create a 3D object with this tool, you have a set of vertices and textures that can be manipulated with specialized 3D editing software. And here again we have excellent open source software for this task, like MeshLab.
MeshLab can be extended via plugins, of which there is an extensive list. Some of them are integrated in the main MeshLab repository, but some others can be found in the MeshLab extra plugins repo. As I wanted to research what sort of measurements I could take on my 3D reconstructions, it looked like writing a MeshLab plugin was a great way to do this and be able to visualize and interact with the results easily.
I had some fun last year with finding optimal rectangles for videoconferences, so somewhat following that line of thought, I wondered how easy was to put an irregular object into an oriented bounding box (OBB) with minimal size, that is, the rectangular parallelepiped of minimal volume that encloses the object. This is called the optimal OBB in the literature. That seemed like a nice fit to try MeshLab plugins and learn how to do measurements on 3D reconstructions at the same time. Also, optimal OBBs have very important applications, such as fast rendering of 3D scenes, collision detection, and others. And optimal packaging might be an application as well indeed.
I put my hands on the task and started to dig into the literature on the topic. There is an exact algorithm to find optimal OBBs found by O’Rourke1, but it is known to be slow (complexity is \(O(N^3)\) being \(N\) the number of vertices) and difficult to implement, so I looked at approximate algorithms. The one from Chang et al2 looked fast and results were very near to O’Rourke’s solution. Also importantly, the authors published Matlab sources for it, so I chose that one for implementation in MeshLab. They called this algorithm HYBBRID because it mixes genetic algorithms with the Nelder-Mead optimization method, that can be used when derivatives for the target function cannot be calculated.
An OBB is defined by a rotation matrix \(R\), the center of the box, and the size of each dimension. The most important part to obtain an optimal OBB is finding the rotation matrix, as once we have it it is trivial to calculate the other parameters by rotating the vertices with \(R^T\) and then finding the minimum and maximum coordinates in the x, y, and z axis. Without digging too much into the details (I defer to the paper for that), the HYBBRID algorithm applies a genetic algorithm to sets of rotation matrices. With the ones that produce the smaller volumes, it applies the Nelder-Mead algorithm to find a local optimum. Finally, it applies a further refinement to the best solution by applying the 2D rotating calipers algorithm3 to each rotated axis. The genetic algorithm does a global sampling of the space of rotation matrices, while Nelder-Mead and 2D rotating calipers try to find a local minimum. The minimization function is not convex and not differentiable, although continuous, so this combination of algorithms works really well.
My C++ implementation for MeshLab has already been merged to the extra plugins repository, and can be found here (this was the original PR). I used the Matlab code as reference, with some improvements in the 2D calipers algorithm and in the calculation of average rotations. The filter adds two meshes to the object to which it is applied, one with the convex hull of the object and another one that defines the bounding box. The convex hull is not strictly necessary, but it reduces the number of vertices you need to care about, speeding up the algorithm. In my tests, the results looked amazingly accurate, and, furthermore, very fast. It took less than 15 seconds for objects of around 100K vertices on my 4 years old laptop (i7 with 8 cores), and the number of iterations of HYBBRID was usually around 6-10.
To build the plugin in the “build” directory, run these commands:
The recursive clone creates a meshlab subfolder. I recommend to compile MeshLab from there (follow these instructions), as otherwise the plugin might crash because the ABI offered by MeshLab is not really meant to be stable.
After compilation, you will get a shared object (build/meshlab/src/distrib/plugins/libfilter_orientedbbox.so) that you need to manually add as a plugin to MeshLab. For that, you need to go to Help -> Plugin Info -> Load Plugins, as instructed in the meshlab extra plugins repository. Once you have done this, the filter should be available in Filters -> Remeshing, Simplification and Reconstruction -> Oriented Bounding Box.
For testing I used this set of images (which are under Creative Commons). I used Meshroom to get a 3D model for them, and then I edited it in MeshLab. To visualize well the results, I used the xray shader (Render -> Shaders -> xray.gdp) that is included in MeshLab and that allows us to “see through” the different object layers. You can also turn on and off different meshes for better visualization. This process is illustrated in the images below.
Using Meshroom to create a 3D model from photographiesThe edited model in MeshLabAfter applying the OBB filter (convex hull hidden)
Below you can see a few more 3D models from this page on which I applied the filter, including of course the mythical tea pot model:
Lamp 3D modelConvex hull of lampLamp in OBB, rendered with x-ray shaderTeapot in OBB, topTeapot in OBB, frontTeapot in OBB, side
And this is pretty much it. I hope you will enjoy playing with the plugin if you take the time to build it. Or, if you don’t, just playing around with Meshroom and MeshLab is really fun time anyway.
These days, in the covid world we live in we have multiple videoconferences every day, with colleagues, family, friends… The average number of people attending has grown, and when I was in a call some time ago, I wondered, what would be the “optimal” way of splitting the videconference application window among the people in the call? What would be the definition of “optimal”? And, in how many ways could the space be split?, as sometimes you might prefer, for instance, one where space is shared equally or one where the current speaker has predominance.
This intrigued me, and I started some research to try to find answers to these questions. I started with the assumption that the videoconference application owns a window on the screen, which is a rectangle (we will call it the bounding rectangle), and we want to divide it in \(N\) different rectangles, being \(N\) the number of people in the call. We can define different criteria for optimizing like, say, dividing equally the window area among the callers. However, for that we need to define mathematically the dividing rectangles, and here is where the first difficulty arises, as the mathematical description changes depending on how you split the window. For instance, two of the ways of dividing the bounding rectangle (let’s call that “rectangulation”) for \(N=3\) are as displayed:
Figure 1 – two possible ways of dividing a rectangle in three
Here we assign a width and a height to each rectangle. Note that optimizing means assigning values to these \(w_i\) and \(h_i\) to fulfill the optimizations criteria, which is like moving the “walls” between rectangles. The height \(h\) and width \(w\) of the bounding rectangle are considered fixed. In each rectangulation, it is possible to expose the implicit restrictions by equations that relate widths and heights of the different rectangles. For the first one in the image, the equations are:
When we optimize we need to take into account these restrictions, which implies that for each rectangulation we have a different optimization problem with different solutions due to having different restrictions/equations in each case. The conclusion is that we need to solve the optimization problem for all possible rectangulations for a given \(N\), and then compare the different optimal values to select the best one. In summary, the steps we need to follow are
Find all possible rectangulations for \(N\) callers
Decide an optimization criteria
Solve the optimization problem for all rectangulations, finding the best sizes for each way of splitting the bounding rectangle
Choose the best rectangulation by finding out which of them has the optimal solution that fulfills better the optimization criteria
In the following sections we will go through each of these steps. I have developed some python code that implements the algorithms and that includes some unit tests that drive them and will be mentioned in different parts of the article. You can find it in github. If on an Ubuntu system, you can install dependencies and clone the repository from the command line with:
N.B. In the mathematical expressions we use one-based indexes but, for practical reasons, the code uses zero-based indexes.
Rectangulating a rectangle
There is quite a bit of mathematical literature on the topic of rectangulations, motivated by applications like placing elements in integrated circuits. Depending on how you define them there can be more or less ways to “rectangulate” a rectangle. We want to take into account all possible rectangulations, but at the same time we need to be careful to avoid duplications. In our framework, a single rectangulation is one that can represent all rectangle sets that can fulfill a given set of equations as those shown at the beginning. Practically, that means that we can slide segments in the rectangulation (without changing the vertical or horizontal orientation) along the limiting segments, as that will not change the relationship that the equations describe. Each of these rectangulations is a class of equivalence of all possible rectangle sets described by a set of equations, and we need to find each of them and then find the optimal rectangles sizes for them, so we cover all possibilities. It turns out that each of these equivalence classes can be represented by what is called in the literature mosaic floorplans or diagonal rectangulations.
How to obtain these rectangulations? I will follow (mostly) the method explained in 4. First, we create a matrix of size \(N\)x\(N\), which conceptually splits the bounding rectangle in cells. We will call it the rectangulation matrix. We number the rectangles consecutively and put the numbers in the matrix diagonal. Then, we choose a permutation (any can do) for the numbers. This permutation determines how the rectangulation will look like. Finally, we follow the order in the permutation to create the rectangles, one by one. To build each rectangle, the rules are
Start from the free cell as left and bottom as possible that can include the cell with the rectangle number
Do not include cells with numbers for other rectangles
Make it as big as possible, with the restriction that it must not surpass the right of the rectangle below it and it must not surpass the top of the rectangle to its left. The bottom and left walls of the bounding rectangle are considered bottom and left rectangles for rectangles touching them.
This defines a map between permutations and diagonal rectangulations that we will call \(\rho\). Figure 2 illustrates this procedure for the rectangulation \(\rho(4,1,3,5,2)\).
Figure 2 – rectangulation for \(\rho(4,1,3,5,2)\)
This is implemented in the do_diagonal_rectangulation() function. There is a test to create random rectangulations that can be run with
Figure 3 shows an example of a run, with numbered rectangles. The sizes are as returned by do_diagonal_rectangulation(), so we can see that all rectangles have part of them in the top-left to bottom-right diagonal.
Figure 3 – rectangulation for N=10
It turns out that this map between permutations and diagonal rectangulations is surjective, so it would be interesting to filter out the permutations that produce duplicated rectangulations to reduce the number of calculations. Fortunately, it has been proved that it is possible to establish a bijection between a subset of permutations, called Baxter permutations, and diagonal rectangulations5.
Baxter permutations
Baxter permutations can be defined by using the generalized pattern avoidance framework6. The way it works is that a sequence is Baxter if there is no subsequence of 4 elements that you can find in it that matches one of the generalized patterns 3-14-2 and 2-41-3. This is an interesting topic but I do not want to digress too much: I have based my implementation on the definition of section 2 of 7. The function is_baxter_permutation() checks whether a sequence is Baxter or not by generating all possible subsequences of 4 elements and checking if they avoid the mentioned patterns. An example using it can be run with
Using Baxter permutations to filter out permutations can save lots of time for bigger \(N\). For instance, for \(N=10\), only around 10% of the permutations are Baxter. There is a closed form formula for the number of Baxter permutations as a function of \(N\)8, so we can compare easily with the total number of permutations, \(N!\).
Rectangle equations
Once we have a rectangulation, we need to extract the equations that define the relations between widths and heights across the rectangles. To do this, we can loop through the rectangulation matrix and detect the limits between rectangles, which define horizontal and vertical segments. When found, we will create an equation that defines that the sum of the widths/heights of the rectangles at each side of the segment must be equal. There will be also two equations for the bounding rectangle that make the sum of width/height of rectangles at the side be equal to the total width/height. Note that these are 2 and not 4 equations, as 2 of the 4 we can extract would be linearly dependent on the full set of equations (this can be seen because if we take the equation on one side and follow the parallel segments equations while moving to the opposite side we can deduce the rectangles that touch the bounding rectangle at the opposite limit). Example of the equation sets that would be extracted are those we have already seen for the rectangulations in figure 1. In the slightly more complex case of figure 2, the equations would be
The function that implements this algorithm is build_rectangulation_equations(). It returns a matrix with the equation coefficients that will be used when optimizing the rectangulations.
The final number of linearly independent equations we will get will be always \(N+1\). This is a corollary of Lemma 2.3 from 9. This lemma defines two operations, “Flip” and “Rotate”, that allow transforming any rectangulation on another one by a finite number of these operations. These operations do not modify the number of segments in the rectangulation. Therefore, we could transform any rectangulation in one having only, say, vertical segments. This rectangulation would have \(N-1\) segments splitting the bounding rectangle, which implies that the original rectangulation had also \(N-1\) segments, because flips and rotations keep the number of segments the same. Finally, after considering two additional equations for the bounding rectangle we find out that the total number of equations for any rectangulation would be \(N+1\).
In each rectangulation, some of the segments will be horizontal, defining \(J\) equations, and others will be vertical, defining \(K\) equations, with \(J+K=N+1\) if we consider now two of the sides of the bounding rectangle segments. We can then define a set of coefficients \(a_{j,i}\) and \(b_{k,i}\) with \(j \in \{1,\ldots,J\}\), \(k \in \{1,\ldots,K\}\) and \(i \in \{1,\ldots,N\}\) to have finally the equations
where the two of them with independent term will be the equations to account for the limits imposed by the bounding rectangle. Note that here we are passing all non-independent terms to the left, so the values for the coefficients can be \(0\), \(1\) or \(-1\).
Optimization problem
Now that have defined arithmetically a rectangulation, we need to decide, what do we want to optimize for? Depending on the circumstances, we might want to optimize with different targets. For instance, we might want to split a window equally among callers, but depending on the rectangulation that could produce very narrow rectangles either horizontally or vertically. So, this cannot be the only thing to consider. In the end, I decided to adopt two criteria:
Make the area the same for all callers as far as possible
Preserve the camera aspect ratio so we can display camera output without cropping
These two criteria overdetermine the system (although this would not be the case if we had selected only criterion 1, as in this case we would have \(2N\) equations in total), so it is not possible to achieve both fully at the same time. So, I used a ponderated optimization function with a coefficient \(c\) to balance between the two parts of the function. With that and taking into account the previously calculated rectangulation equations, we can pose the optimization problem as
where \(w\) and \(h\) are the width and height of the bounding rectangle and \(w_i\) and \(h_i\) are the width and height of the \(i\)-th rectangle of the rectangulation. The coefficient \(k\) is the desirable width over height ratio for the rectangles, which we will want usually to be the same as the usual camera ratio between \(x\) and \(y\) resolution. In the first term of the objective function \(F\) the difference between the rectangles areas and the area that we would have if the total area was equally split is calculated, while the second term measures how far we are from the target aspect ratio in each rectangle.
Note that in the equation we multiply \(c\) by the the squared total height. This is needed so resulting sizes are scaled when \(w\) and \(h\) are scaled. That is, when multiplying the size of the bounding rectangle by a constant \(q > 0\) so \(w \rightarrow qw\) and \(h \rightarrow qh\), we would like the sizes of the solution to scale by the same value. We can see that is actually the case if we pose a new optimization problem for the scaled bounding rectangle (with new variables \(w_i^\prime\) and \(h_i^\prime\)) and then substitute in the new target function \(F^\prime\):
The constant \(q^4\) does not affect the location of the minima of the function, so we can ignore it. Then, if we do the change of variable \(w_i^\prime = q w_i\) and \(h_i^\prime = q h_i\) we end up with the original objective function \(F\), which proves that the minima of \(F^\prime\) are \(q\) times the minima of \(F\). The constraints also behave well under the change of variables: the equations without independent terms are unaffected by scaling, and for the other two, when we replace \(w\) by \(qw\) and \(h\) by \(qh\) we see that \(q\) can go to the left side of the equations and we would have \(w_i^\prime/q\) and \(h_i^\prime/q\) in all terms, showing that with the change of variables we would have the original minimization problem.
What this is telling us is that solutions to this problem depend only on \(N\), \(k\), \(c\) and the ratio \(w/h\), minus scaling. If we have a solution for a set of these variables, we know the solution if we scale proportionally the bounding rectangle.
Something similar happens if we scale only one of the dimensions, with the difference that this would happen only if we scale \(k\) too, so \(w \rightarrow qw\) and \(k \rightarrow qk\) would scale widths by \(q\), while \(h \rightarrow qh\) and \(k \rightarrow k/q\) would scale heights by \(k\).
Finally, this is defining the solution to one rectangulation, determined by a given Baxter permutation that we will call \(r\), that defines a set of optimal values \(\{w_1^r,\ldots,w_N^r,h_1^r,\ldots,h_N^r\}\). The final solution would be the one that minimizes \(F\) across the optimal values for all possible rectangulations. If we create a set \(S_{B(N)}\) where each element is a set with the optimal solution to a rectangulation, being \(B(N)\) the total number of rectangulations, the global optimal values would be
It is possible to solve the optimization problem of the last section in a fully analytical way. For that, we can use Lagrange multipliers to include the restrictions in a new optimization function, and then find the derivatives to be able to find the extrema. The python sympy module comes in handy for solving analytically this problem: this is implemented by the solve_rectangle_eqs() function. There is a test that uses it:
However, it turned out that when we have enough rectangles, sympy can take a very long time to get a solution, and we have many problems to solve, one for each possible rectangulation. Therefore, I used in the end the minimize function from scipy library to solve numerically the problem. We can calculate analytically the Jacobian for the objective function and provide good initial estimates by using the proportions from the diagonal rectangulation. The minimize function can also incorporate constraints, so we can easily add the rectangulation equations to the mix. Scipy will choose the SLSQP algorithm to perform the minimization, due to these constraints. The results are consistently fast and accurate. The function that implements this is minimize_rectangulation(). Some of the tests that use it can be run with:
The solution for the rectangulation in figure 3 for a window of size 320×180 for \(c=0.05\) and \(k=1.5\) can be seen in figure 4. The area element of \(F\) is predominant in this case.
Figure 4 – figure 3 rectangulation with sizes minimizing the target function
Results
Now that we have everything in place we can answer the questions we posed at the beginning of the post. For instance, in a videoconference with 5 callers, what would be the ideal window split? For this, the function get_best_rect_for_window() calculates all possible rectangulations for a given \(N\), making sure we filter non-Baxter permutations, then minimizes according to the target function we defined previously (by using minimize_rectangulation()), and finally selects the rectangulation that produces the global smallest value for that target. A test that calculates the optimum for \(N=5\), \(c=0.05\), \(k=1.33\), \(w=320\) and \(h=180\) can be run with:
Visually, we get the rectangulation shown in figure 5.
Figure 5: optimal rectangulation for N=5, k=1.33
How things change as we start to resize the window? One of the tests shows what happens when the ratio \(w/h\) changes (remember that solutions simply scale if we scale width and height with the same constant, so this ratio interests us more than real resolutions sizes in a monitor). For \(c=0.05\), \(k=1.33\) and area \(wh=320 \cdot 200 = 57600\) pixels, this test finds the optima for different ratios:
We can see the optimal rectangulations for different ratios calculated by this test in figure 6. It is also interesting to see how things change if we change the balance between the members of the objective function. In figure 7 we show the solutions for same test but with \(c=0.5\).
Figure 6 – optimal rectangulations for N=5, c=0.05 and different w/h ratios
Figure 7 – optimal rectangulations for N=5, c=0.5 and different w/h ratios
Outcome is in general lines as you would expect. Having a prime number of callers forces rectangles to not be the same all the time, but the algorithm follows the optimization criteria as far as possible and makes a reasonable job. With a bigger \(c\) we see that having rectangles with a width/height ratio near to \(k\) starts to predominate and difference between areas starts to grow.
Conclusion
We have seen in this post the ways in which a rectangle can be split in another rectangles and how we can optimize the layout with different criteria. This of course has more applications than splitting the window of a video-conference application in different camera views, being the most well known one optimizing the placing of components on an integrated circuit. In any case, I had not expected to go this far when I started to work on this problem, but it was a fun ride that hopefully you have enjoyed as well, especially if you have gone this far in the reading!
In chapter 5 of his mind-blowing “The Road to Reality”, Penrose devotes a section to complex powers, that is, to the solutions to
$$w^z~~~\text{with}~~~w,z \in \mathbb{C}$$
In this post I develop a bit more what he exposes and explore what the solutions look like with the help of some simple Python scripts. The scripts can be found in this github repo, and all the figures in this post can be replicated by running
git clone https://github.com/alfonsosanchezbeato/exponential-spiral.git
cd exponential-spiral; ./spiral_examples.py
The scripts make use of numpy and matplotlib, so make sure those are installed before running them.
Now, let’s develop the math behind this. The values for \(w^z\) can be found by using the exponential function as
In this equation, “log” is the complex natural logarithm multi-valued function, while “Log” is one of its branches, concretely the principal value, whose imaginary part lies in the interval \((−\pi, \pi]\). In the equation we reflect the fact that \(\log{w}=\text{Log}~w + 2\pi ni\) with \(n \in \mathbb{Z}\). This shows the remarkable fact that, in the general case, we have infinite solutions for the equation. For the rest of the discussion we will separate \(w^z\) as follows:
with constant \(C=e^{z~\text{Log}~w}\) and the rest being the sequence \(F_n=e^{2\pi nzi}\). Being \(C\) a complex constant that multiplies \(F_n\), the only influence it has is to rotate and scale equally all solutions. Noticeably, \(w\) appears only in this constant, which shows us that the \(z\) values are what is really determinant for the number and general shape of the solutions. Therefore, we will concentrate in analyzing the behavior of \(F_n\), by seeing what solutions we can find when we restrict \(z\) to different domains.
Starting by restricting \(z\) to integers (\(z \in \mathbb{Z}\)), it is easy to see that there is only one resulting solution in this case, as the factor \(F_n=e^{2\pi nzi}=1\) in this case (it just rotates the solution \(2\pi\) radians an integer number of times, leaving it unmodified). As expected, a complex number to an integer power has only one solution.
If we let \(z\) be a rational number (\(z=p/q\), being \(p\) and \(q\) integers chosen so we have the canonical form), we obtain
$$F_n=e^{2\pi\frac{pn}{q} i}$$
which makes the sequence \(F_n\) periodic with period \(q\), that is, there are \(q\) solutions for the equation. So we have two solutions for \(w^{1/2}\), three for \(w^{1/3}\), etc., as expected as that is the number of solutions for square roots, cube roots and so on. The values will be the vertex of a regular polygon in the complex plane. For instance, in figure 1 the solutions for \(2^{1/5}\) are displayed.
Fig. 1: The five solutions to \(2^{1/5}\)
If \(z\) is real, \(e^{2\pi nzi}\) is not periodic anymore has infinite solutions in the unit circle, and therefore \(w^z\) has infinite values that lie on a circle of radius \(|C|\).
In the more general case, \(z \in \mathbb{C}\), that is, \(z=a+bi\) being \(a\) and \(b\) real numbers, and we have
$$F_n=e^{-2\pi bn}e^{2\pi ani}.$$
There is now a scaling factor, \(e^{-2\pi bn}\) that makes the module of the solutions vary with \(n\), scattering them across the complex plane, while \(e^{2\pi ani}\) rotates them as \(n\) changes. The result is an infinite number of solutions for \(w^z\) that lie in an equiangular spiral in the complex plane. The spiral can be seen if we change the domain of \(F\) to \(\mathbb{R}\), this is
In figure 2 we can see one example which shows some solutions to \(2^{0.4-0.1i}\), plus the spiral that passes over them.
Fig. 2: Roots and spiral for \(2^{0.4-0.1i}\)
In fact, in Penrose’s book it is stated that these values are found in the intersection of two equiangular spirals, although he leaves finding them as an exercise for the reader (problem 5.9).
Let’s see then if we can find more spirals that cross these points. We are searching for functions that have the same value as \(F(t)\) when \(t\) is an integer. We can easily verify that the family of functions
are compatible with this restriction, as \(e^{2\pi kti}=1\) in that case (integer \(t\)). Figures 3 and 4 represent again some solutions to \(2^{0.4-0.1i}\), \(F(t)\) (which is the same as the spiral for \(k=0\)), plus the spirals for \(k=-1\) and \(k=1\) respectively. We can see there that the solutions lie in the intersection of two spirals indeed.
Fig. 4: Roots for \(2^{0.4-0.1i}\) plus spirals for k=0 and k=1
If we superpose these 3 spirals, the ones for \(k=1\) and \(k=-1\) cross also in places different to the complex powers, as can be seen in figure 5. But, if we choose two consecutive numbers for \(k\), the two spirals will cross only in the solutions to \(w^z\). See, for instance, figure 6 where the spirals for \(k=\{-2,-1\}\) are plotted. We see that any pair of such spirals fulfills Penrose’s description.
Fig. 5: Roots for \(2^{0.4-0.1i}\) plus spirals for k=-1,0,1
Fig. 6: Roots for \(2^{0.4-0.1i}\) plus spirals for k=-1,-2
In general, the number of places at which two spirals cross depends on the difference between their \(k\)-number. If we have, say, \(F_k’\) and \(F_l’\) with \(k>l\), they will cross when
That is, they will cross when \(t\) is an integer (at the solutions to \(w^z\)) and also at \(k-l-1\) points between consecutive solutions.
Let’s see now another interesting special case: when \(z=bi\), that is, it is pure imaginary. In this case, \(e^{2\pi ati}\) is \(1\), and there is no turn in the complex plane when \(t\) grows. We end up with the spiral \(F(t)\) degenerating to a half-line that starts at the origin (which is reached when \(t=\infty\) if \(b>0\)). This can be appreciated in figure 7, where the line and the spirals for \(k=-1\) and \(k=1\) are plotted for \(20^{0.1i}\). The two spirals are mirrored around the half-line.
Fig. 7: Roots for \(10^{0.1i}\), \(F(t)\), and spirals for k=-1,1
Digging more into this case, it turns out that a pure imaginary number to a pure imaginary power can produce a real result. For instance, for \(i^{0.1i}\), we see in figure 8 that the roots are in the half-positive real line.
Fig. 8: Roots for \(i^{0.1i}\), \(F(t)\), and spirals for k=-1,1
That something like this can produce real numbers is a curiosity that has intrigued historically mathematicians (\(i^i\) has real values too!). And with this I finish the post. It is really amusing to start playing with the values of \(w\) and \(z\), if you want to do so you can use the python scripts I pointed to in the beginning of the post. I hope you enjoyed the post as much as I did writing it.